Most papers using reinforcement learning these days use the policy gradient class of learning. In this post, I will cover a basic tutorial of policy gradient, uncover some confusion on using baseline and regularization and give some suggestion for debugging these learning algorithms that I have found useful in the past.
Policy gradient methods is a class of reinforcement learning algorithm that optimize the reinforcement learning (RL) objective by performing gradient descent on the policy parameters. As opposed to value function based methods (SARSA, Q-learning), the central object of study in policy gradient methods is a policy function 


The objective 

Policy Gradient Theorem
Let 



The expected total discounted reward can be expressed as:
![J^\pi = E[\sum_{t\ge 0} \gamma^t r_t] = \sum_s \mu(s) V^\pi(s)](http://s0.wp.com/latex.php?latex=J%5E%5Cpi+%3D+E%5B%5Csum_%7Bt%5Cge+0%7D+%5Cgamma%5Et+r_t%5D+%3D+%5Csum_s+%5Cmu%28s%29+V%5E%5Cpi%28s%29&bg=ffffff&fg=404040&s=0&c=20201002)
See my previous post if you don’t know what 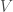




using 

so now we have an expression for 

we will change the notation as 

unfolding this equation gives us (verify it for yourself):

where 

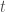

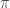
Discounted unnormalized visitation probability: The term 




and for finite horizon with 


so in either case the sum of 
using the notation we have:

and which gives us:

or using the notation of Kakade and Langford 2002, we define 

Another way to express objective: Using the notation of visitation distribution, allows us to express the expected total discounted reward objective in a form that gives another interpretation to the policy gradient theorem. Observe that:
![J = E[\sum_{t \ge 0} \gamma^t r_t] = \sum_{t \ge 0} \gamma^t E[r_t]](http://s0.wp.com/latex.php?latex=J+%3D+E%5B%5Csum_%7Bt+%5Cge+0%7D+%5Cgamma%5Et+r_t%5D+%3D+%5Csum_%7Bt+%5Cge+0%7D+%5Cgamma%5Et+E%5Br_t%5D&bg=ffffff&fg=404040&s=0&c=20201002)
reward 


![E[r_t] = E[R(s_t, a_{t+1})] = \sum_{s} P(s_t = s) \sum_a \pi(a \mid s)](http://s0.wp.com/latex.php?latex=E%5Br_t%5D+%3D+E%5BR%28s_t%2C+a_%7Bt%2B1%7D%29%5D+%3D+%5Csum_%7Bs%7D+P%28s_t+%3D+s%29+%5Csum_a+%5Cpi%28a+%5Cmid+s%29&bg=ffffff&fg=404040&s=0&c=20201002)
Plugging it in we get:
![J^\pi = \sum_{t \ge 0} \gamma^t E[r_t] =\sum_{t \ge 0} \gamma^t\sum_{s} P(s_t = s) \sum_a \pi(a \mid s)](http://s0.wp.com/latex.php?latex=J%5E%5Cpi+%3D+%5Csum_%7Bt+%5Cge+0%7D+%5Cgamma%5Et+E%5Br_t%5D+%3D%5Csum_%7Bt+%5Cge+0%7D+%5Cgamma%5Et%5Csum_%7Bs%7D+P%28s_t+%3D+s%29+%5Csum_a+%5Cpi%28a+%5Cmid+s%29&bg=ffffff&fg=404040&s=0&c=20201002)
Rearranging the terms we get:
![J^\pi = \sum_{t \ge 0} \gamma^t E[r_t] =\sum_{s} P(s_t = s) \sum_{t \ge 0} \gamma^t\sum_{s} P(s_{t-1} = s) \sum_a \pi(a \mid s)](http://s0.wp.com/latex.php?latex=J%5E%5Cpi+%3D+%5Csum_%7Bt+%5Cge+0%7D+%5Cgamma%5Et+E%5Br_t%5D+%3D%5Csum_%7Bs%7D+P%28s_t+%3D+s%29+%5Csum_%7Bt+%5Cge+0%7D+%5Cgamma%5Et%5Csum_%7Bs%7D+P%28s_%7Bt-1%7D+%3D+s%29+%5Csum_a+%5Cpi%28a+%5Cmid+s%29&bg=ffffff&fg=404040&s=0&c=20201002)
and then using the notation of 

Compare this with the gradient of the objective:

It appears as if we don’t take gradient over the term 

Corollary*:

Proof:


comparing the two equations and rearranging gives the result.
The REINFORCE algorithm
REINFORCE algorithm (Williams 1992) comes directly from approximating the gradient given by the policy gradient objective. Firstly, we will review sampling for the wider audience.
Brief Summary on Sampling: Given an expectation ![E_p[f] = \sum_s f(s) p(s)](http://s0.wp.com/latex.php?latex=E_p%5Bf%5D+%3D+%5Csum_s+f%28s%29+p%28s%29+&bg=ffffff&fg=404040&s=0&c=20201002)

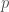




![E_p[f]](http://s0.wp.com/latex.php?latex=E_p%5Bf%5D&bg=ffffff&fg=404040&s=0&c=20201002)


![E_{x_i \sim p}[\sum_{i=1}^N \frac{f(x_i)}{N}] = \sum_{i=1}^N \frac{1}{N} E_{x_i \sim p}[f(x_i)] =\sum_{i=1}^N \frac{1}{N} E_p[f] = E_p[f]](http://s0.wp.com/latex.php?latex=E_%7Bx_i+%5Csim+p%7D%5B%5Csum_%7Bi%3D1%7D%5EN+%5Cfrac%7Bf%28x_i%29%7D%7BN%7D%5D+%3D+%5Csum_%7Bi%3D1%7D%5EN+%5Cfrac%7B1%7D%7BN%7D+E_%7Bx_i+%5Csim+p%7D%5Bf%28x_i%29%5D+%3D%5Csum_%7Bi%3D1%7D%5EN+%5Cfrac%7B1%7D%7BN%7D+E_p%5Bf%5D+%3D+E_p%5Bf%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![var(X) = E[(X- E[X])^2]](http://s0.wp.com/latex.php?latex=var%28X%29+%3D+E%5B%28X-+E%5BX%5D%29%5E2%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![var(\sum_{i=1}^N \frac{1}{N}E_{x_i \sim p}[f(x_i)]) = \frac{var(x)}{N}](http://s0.wp.com/latex.php?latex=var%28%5Csum_%7Bi%3D1%7D%5EN+%5Cfrac%7B1%7D%7BN%7DE_%7Bx_i+%5Csim+p%7D%5Bf%28x_i%29%5D%29+%3D+%5Cfrac%7Bvar%28x%29%7D%7BN%7D&bg=ffffff&fg=404040&s=0&c=20201002)

Vanilla REINFORCE: A quick look at the policy gradient tells us that we can never compute it exactly except for tiny MDP. We therefore want to approximate the gradient of


Let’s say we sample a rollout 



Note that we only use a single sample here (
After this approximation we have,

If we knew 
Unfortunately, the summation is not written in the form of an expectation i.e. 
![\sum_a (\nabla p(a)) f(a) = \sum_a p(a) (\nabla \ln p(a) )f(a) = E_{a \sim p(.)}[ \nabla \ln p(a) f(a)]](http://s0.wp.com/latex.php?latex=%5Csum_a+%28%5Cnabla+p%28a%29%29+f%28a%29+%3D+%5Csum_a+p%28a%29%C2%A0+%28%5Cnabla+%5Cln+p%28a%29+%29f%28a%29+%3D+E_%7Ba+%5Csim+p%28.%29%7D%5B+%5Cnabla+%5Cln+p%28a%29+f%28a%29%5D&bg=ffffff&fg=404040&s=0&c=20201002)

We already have samples from 

We are still left with estimating 
![Q^\pi(s, a) = E[\sum_{t \ge 0} \gamma^t r_t \mid s_0=s, a_1=a]](http://s0.wp.com/latex.php?latex=Q%5E%5Cpi%28s%2C+a%29+%3D+E%5B%5Csum_%7Bt+%5Cge+0%7D+%5Cgamma%5Et+r_t+%5Cmid+s_0%3Ds%2C+a_1%3Da%5D&bg=ffffff&fg=404040&s=0&c=20201002)


After these approximations, we are ready to state the vanilla REINFORCE algorithm:
The REINFORCE Algorithm
- Initialize the parameters
randomly.
- Generate rollout
using the current policy
- Do gradient ascent:
 randomly.
randomly. using the current policy
using the current policy 

Keep the Samples Unbiased. Throw away Rollouts after Update.
Our entire derivation approximating the value of
Problem with REINFORCE:
REINFORCE is not a very good learning algorithm for anything interesting. Few main issues with it are:
- No Exogenous Randomization: REINFORCE uses the same policy for exploration as the one being optimized. There is no way to control the flow of exploration or way to add exogenous randomization. This can hinder exploration since the policy can get stuck in specific regions and may not be able to explore outside.
- Variance: We used a single rollout above to make several approximations. This can affect the variance of our estimate of the gradient. Having high-variance estimate can prohibit learning.
- Degenerate Solutions: REINFORCE can get stuck in degenerate solutions where the policy can suddenly become deterministic while being far from optimal. Once the policy is deterministic, the updates stop since our estimated gradient:

becomes 0. This effectively kills the learning and it has to be restarted. This situation is frequently encountered in practice and we will call it the entropy-collapse issue. Q-learning does not suffer from this degeneracy.
Next we will discuss some solutions to above problem and discuss few methods for debugging.
No Exogenous Randomization
REINFORCE’s inability to separate the exploration policy from the policy being optimized is one of its biggest weakness. There are atleast two different ways in which this has been addressed. The first approach uses a warm start to initialize the policy using behaviour cloning or imitation learning. This also makes sense from deployment point of view where we have to place our agent in the real world in order to perform reinforcement learning and thus don’t want the start policy to be randomly initialized (imagine asking users to chat with a randomly intialized conversation model!). One can naively hope that warm start will enable the policy to explore in the right region of the problem.
The other approach is to use a separate exploration policy and unbias the gradients by using importance weights. However this approach may not be suitable if the policy has close to 0 mass on actions which are chosen by the exploration policy.
Another line of research involves designing intrinsic reward function (pseudo-counts, prediction error, variance of ensemble) to incentivize the policy to eventually learn to explore the desired state space. However, these approaches generally range from having theoretical guarantees in tabular MDPs (e.g., MBIE-EB count based exploration) to having no theoretical guarantee at all (e.g., prediction error).
Reducing Variance through Control Variate
We made a remark earlier pertaining to the variance of the estimate of the gradient for the REINFORCE algorithm. Let’s make it more formalized:
Given a rollout, 


This estimate is unbiased i.e. ![E[X(\tau)] = \nabla J^\pi](http://s0.wp.com/latex.php?latex=E%5BX%28%5Ctau%29%5D+%3D+%5Cnabla+J%5E%5Cpi&bg=ffffff&fg=404040&s=0&c=20201002)
![Var(X) = E[(X(\tau) -\nabla J) (X(\tau) - \nabla J)^T]](http://s0.wp.com/latex.php?latex=Var%28X%29+%3D+E%5B%28X%28%5Ctau%29+-%5Cnabla+J%29+%28X%28%5Ctau%29+-+%5Cnabla+J%29%5ET%5D&bg=ffffff&fg=404040&s=0&c=20201002)

Control-Variate: Let 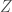
![E[Z]](http://s0.wp.com/latex.php?latex=E%5BZ%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![Y = X + c (Z - E[Z])](http://s0.wp.com/latex.php?latex=Y+%3D+X+%2B+c+%28Z+-+E%5BZ%5D%29&bg=ffffff&fg=404040&s=0&c=20201002)
![E[Y] = E[X] + c E[Z] - c E[Z] = \mu](http://s0.wp.com/latex.php?latex=E%5BY%5D+%3D+E%5BX%5D+%2B+c+E%5BZ%5D+-+c+E%5BZ%5D+%3D+%5Cmu&bg=ffffff&fg=404040&s=0&c=20201002)



Reinforce Baseline: We need to define a control variable to reduce variance.
We define it as: 

![E[Z(\tau)] = 0](http://s0.wp.com/latex.php?latex=E%5BZ%28%5Ctau%29%5D+%3D+0&bg=ffffff&fg=404040&s=0&c=20201002)
![E[Z(\tau)] = E[\sum_{t \ge 0} \gamma^t \nabla \ln \pi(a_{t+1} \mid s_t) b(s_t) ]](http://s0.wp.com/latex.php?latex=E%5BZ%28%5Ctau%29%5D+%3D+E%5B%5Csum_%7Bt+%5Cge+0%7D+%5Cgamma%5Et+%5Cnabla+%5Cln+%5Cpi%28a_%7Bt%2B1%7D+%5Cmid+s_t%29+b%28s_t%29+%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![E[Z(\tau)] = \sum_{t \ge 0} \gamma^t E[\nabla \ln \pi(a_{t+1} \mid s_t) b(s_t) ]](http://s0.wp.com/latex.php?latex=E%5BZ%28%5Ctau%29%5D+%3D+%5Csum_%7Bt+%5Cge+0%7D+%5Cgamma%5Et+E%5B%5Cnabla+%5Cln+%5Cpi%28a_%7Bt%2B1%7D+%5Cmid+s_t%29+b%28s_t%29+%5D&bg=ffffff&fg=404040&s=0&c=20201002)




We will further set the value of 
![Y(\tau) = X(\tau) - (Z(\tau) - E[Z]) =\sum_{t \ge 0} \gamma^t \nabla \ln \pi(a_{t+1} \mid s_t) \{ Q(s_t, a_{t+1}) - b(s_t) \}](http://s0.wp.com/latex.php?latex=Y%28%5Ctau%29+%3D+X%28%5Ctau%29+-+%28Z%28%5Ctau%29+-+E%5BZ%5D%29+%3D%5Csum_%7Bt+%5Cge+0%7D+%5Cgamma%5Et+%5Cnabla+%5Cln+%5Cpi%28a_%7Bt%2B1%7D+%5Cmid+s_t%29+%5C%7B+Q%28s_t%2C+a_%7Bt%2B1%7D%29+-+b%28s_t%29+%5C%7D&bg=ffffff&fg=404040&s=0&c=20201002)

Proof of Variance Reduction(*): We still haven’t chosen a baseline function and we set the value of 


![= Var(X) + E[(Z - E[Z])^2] - 2 E[(X- E[X])(Z-E[Z])]](http://s0.wp.com/latex.php?latex=%3D+Var%28X%29+%2B+E%5B%28Z+-+E%5BZ%5D%29%5E2%5D+-+2+E%5B%28X-+E%5BX%5D%29%28Z-E%5BZ%5D%29%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![= Var(X) + E[Z^2] - 2 E[XZ] + 2 E[X] E[Z] = Var(X) + E[Z(Z - 2X)]](http://s0.wp.com/latex.php?latex=%3D+Var%28X%29+%2B+E%5BZ%5E2%5D+-+2+E%5BXZ%5D+%2B+2+E%5BX%5D+E%5BZ%5D+%3D+Var%28X%29+%2B+E%5BZ%28Z+-+2X%29%5D&bg=ffffff&fg=404040&s=0&c=20201002)
Where ![E[Z(Z-2X)] = E[ \nabla p(a_1 \mid s_0) b(s_0) \{\nabla p(a_1 \mid s_0) \{ b(s_0) - Q(s_1, a_1)\} \}]](http://s0.wp.com/latex.php?latex=E%5BZ%28Z-2X%29%5D+%3D+E%5B+%5Cnabla+p%28a_1+%5Cmid+s_0%29+b%28s_0%29%C2%A0+%5C%7B%5Cnabla+p%28a_1+%5Cmid+s_0%29+%5C%7B+b%28s_0%29+-+Q%28s_1%2C+a_1%29%5C%7D+%5C%7D%5D&bg=ffffff&fg=404040&s=0&c=20201002)
which can be simplified to
![= E[ \|\nabla p(a_1 \mid s_0) \|^2 b(s_0) \{ b(s_0) - Q(s_0, a_1) \}]](http://s0.wp.com/latex.php?latex=%3D+E%5B%C2%A0+%5C%7C%5Cnabla+p%28a_1+%5Cmid+s_0%29+%5C%7C%5E2+b%28s_0%29+%5C%7B+b%28s_0%29+-+Q%28s_0%2C+a_1%29+%5C%7D%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![= E[\|\nabla p(a_1 \mid s_0) \|^2] b^2(s_0) - b(s_0) E[ \|\nabla p(a_1 \mid s_0) \|^2 Q(s_0, a_1)]](http://s0.wp.com/latex.php?latex=%3D+E%5B%5C%7C%5Cnabla+p%28a_1+%5Cmid+s_0%29+%5C%7C%5E2%5D+b%5E2%28s_0%29+-+b%28s_0%29+E%5B+%5C%7C%5Cnabla+p%28a_1+%5Cmid+s_0%29+%5C%7C%5E2+Q%28s_0%2C+a_1%29%5D&bg=ffffff&fg=404040&s=0&c=20201002)
setting it to 0 gives the optimal baseline as ![b(s_0) = \frac{E[ \|\nabla p(a_1 \mid s_0) \|^2 Q(s_0, a_1)]}{E[\|\nabla p(a_1 \mid s_0) \|^2]}](http://s0.wp.com/latex.php?latex=b%28s_0%29+%3D+%5Cfrac%7BE%5B+%5C%7C%5Cnabla+p%28a_1+%5Cmid+s_0%29+%5C%7C%5E2+Q%28s_0%2C+a_1%29%5D%7D%7BE%5B%5C%7C%5Cnabla+p%28a_1+%5Cmid+s_0%29+%5C%7C%5E2%5D%7D&bg=ffffff&fg=404040&s=0&c=20201002)
If one makes an independency assumption between 

![b(s_0) = \frac{E[ \|\nabla p(a_1 \mid s_0) \|^2 Q(s_0, a_1)]}{E[\|\nabla p(a_1 \mid s_0) \|^2]} =\frac{E[ \|\nabla p(a_1 \mid s_0) \|^2] E[Q(s_0, a_1)]}{E[\|\nabla p(a_1 \mid s_0) \|^2]} =E[Q(s_0, a_1)] = V(s_0)](http://s0.wp.com/latex.php?latex=b%28s_0%29+%3D+%5Cfrac%7BE%5B+%5C%7C%5Cnabla+p%28a_1+%5Cmid+s_0%29+%5C%7C%5E2+Q%28s_0%2C+a_1%29%5D%7D%7BE%5B%5C%7C%5Cnabla+p%28a_1+%5Cmid+s_0%29+%5C%7C%5E2%5D%7D+%3D%5Cfrac%7BE%5B+%5C%7C%5Cnabla+p%28a_1+%5Cmid+s_0%29+%5C%7C%5E2%5D+E%5BQ%28s_0%2C+a_1%29%5D%7D%7BE%5B%5C%7C%5Cnabla+p%28a_1+%5Cmid+s_0%29+%5C%7C%5E2%5D%7D+%3DE%5BQ%28s_0%2C+a_1%29%5D+%3D+V%28s_0%29&bg=ffffff&fg=404040&s=0&c=20201002)
One can do a similar analysis for multi-step reinforcement learning and derive the optimal policy. While the optimal policy has been known for many years, all empirical application of REINFORCE or its derivative (in which I count actor-critic methods) use an approximated baseline given by the state-value function 
Importance of Regularization
REINFORCE can get stuck in degenerate solutions as pointed out before. To avoid this degeneracy, a common tactic of regularizing the objective with the entropy of the policy or KL-divergence from a reference policy is adopted. We will focus on the former method here. The entropy regularized objective is given below:

where 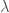

Most researchers however use biased gradients given below:


Entropy regularized objective will no longer follow our classic Bellman optimality conditions and the optimal policy no longer remains deterministic. An easy verification of this is to set 

Evaluating Training Progress
When training a classifier for a task like ImageNet, one generally monitors the training error and the error on a held out tune set. The decrease in training error tells that your model has sufficient capacity and an increase in tune set indicates potential overfitting. Consider, the approximated gradient of the objective for REINFORCE:

the standard way to program this using pytorch or tensorflow is to define the loss variable:

when doing gradient descent on this variable we get the same gradient as the approximation gives us. This does not make 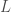
Monitoring the substitute loss is not the same as monitoring the actual training loss when doing supervised learning. To begin with, notice that the substitute loss is positive when the agent receives only positive reward and it is negative when the agent only receives negative rewards. This is counterintuitive as one ideally associates high loss with low return. So why is this so?
This happens cause when all the rewards are positive then the loss is positive and the only way the agent can reduce it is by pushing the term 
Thus, instead of monitoring the substitute loss, one can monitor two things: (i) the total reward received by the agent which also represents an unbiased estimate of the actual objective and (ii) the entropy of the policy. Ideally the total reward achieved by the agent should increase and the entropy of the policy should decrease. Any stagnation means the learning is not happening effectively.
Major Failure Case for Policy Gradient
Policy gradient methods have no guarantees in theory or practice. A simple example which can be used to demonstrate this is from John Langford. There are 





With a close to 1 probability, any rollout will fail to reach the destination state where it earns a reward and therefore will not cause any meaningful learning when using on-policy policy gradient methods. It will require exponentially many samples for it to reach the state
Conclusion
Despite its flaws policy gradient methods are used widely for all sort of AI applications. One reason behind its widespread use is their remarkable similarity to supervised learning with which most empiricists are widely familiar. Thus, one can train their favourite dialogue model using REINFORCE by simply multiplying the log probabilities with a value term. Further, variants of policy gradient methods like PPO perform much better and are reasonable baselines. However, it could also be the case that most people don’t care about guarantees as long as they can solve their favourite childhood game and as a field we must guard against this trend as we move towards more serious applications of these algorithms.