Problems in Artificial Intelligence (AI) are generally approached by solving a dataset/setup that is a proxy of the real world. This is a fairly old practice going back to the start of AI as a field. Some important milestones along the way include the ATIS dataset for natural language understanding (1990s), MNIST dataset for digit recognition (1990s) and ImageNet for visual object detection (2000s). All the above datasets have a commonality which is they are real samples of the actual problem distribution i.e., each sample in this dataset can actually take place in real life. An image of a flower in the ImageNet dataset can actually be found in real life. We will distinguish between datasets and setups, e.g., ImageNet is a dataset whereas Atari games is a setup. However, eventually setups are used to generate dataset of some form so for the remaining post we will treat setups as datasets (albeit with control over how to generate this dataset).
In contrast, another trend has become very popular for certain problems whereby the samples in the dataset are not real life samples but synthetic samples. Examples of real and synthetic datasets are shown in this Figure:

Figure: Examples of real and synthetic datasets. The real datasets on the left show natural language text and real images. The synthetic datasets on the right show templated text and synthetic images.
But what does it formally mean for a dataset to be synthetic? Without a formal definition we will not be able to make complete sense of what we are critiquing.
Formal Definition of a Synthetic Dataset
Let 






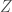

We will consider two types of synthetic dataset distribution 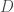
Synthetic Datasets of First Kind (Exclusive)
Definition: 
Example: The synthetic image dataset shown in Figure 1 is of first kind since not even a single image in this dataset will be occur in real life.
Synthetic Datasets of Second Kind (Inclusive)
Definition:

Example: The synthetic text dataset shown in Figure 2 is of second kind as whereas these templated sentences can occur in real life they represent only a limited form of real life free-form texts.
Example: Consider an object detection dataset that is created using the following approach. We find 1000 randomly uniformly chosen object categories in the world and for each category, select 10,000 randomly chosen images. Such a dataset will not be synthetic as every object has a non-zero chance of selection. For current purpose, I will avoid the discussion of whether this can still constitute a null set with respect to some measure.
The above definition is quite conservative. There could be other instances where a dataset can be considered synthetic. For example, a highly biased dataset distribution can be considered synthetic. However, the above definition does not use any thresholds (e.g., some bound on KL-divergence between
Are Synthetic Datasets Useful?
Since the trained models on these datasets/setups are not directly useful in real life, therefore, a debate has arisen in the community if such synthetic datasets are useful at all.
Synthetic datasets can be useful if they are designed with a specific objective in mind.
I would argue that synthetic datasets are useful if they are designed with a specific objective in mind. I argue that there are three main useful reasons for creating a new dataset.
- Generating Real Life Samples: An obvious use of datasets is to predict the performance of a system in real life. If this is your aim then you should try to create a dataset that is as close to the real world as possible for accurate prediction. An example of this trend is the ImageNet dataset.
- Ablating Real Life Phenomenon: Often times the real life problem is far too complex and challenging. A common solution is to consider a specific phenomenon and “ablate” away the others. Let’s say you are interested in creating autonomous vehicles. This involves solving challenges in planning, computer vision and control. Directly creating a setup where the car navigates in the city is dangerous and not to say illegal. Therefore, to make progress towards this difficult challenge, people ablate away other phenomenons to focus on a single challenge. For example, if you are designing a planning component then you can create setup where the vision and control problems have been solved. Or if you are solving the computer vision aspect then you can assume access to a set of images taken from a camera mounted on top of a car. You can then focus on doing object detection and localization in these static images without worrying about how the car is moving around. You can even create simulations to ablate phenomenons. If this is your goal then the dataset has to be created to be as realistic as possible in terms of the phenomenon you are interested in while ablating away the other challenges. The ablation can be done by giving “oracle” access to the solution of those challenges (e.g., an oracle planner) or making the problem really easy (e.g., using simple images). Most of the empirical side of my research has been in this category (e.g., [EMNLP 2017], [EMNLP 2018]). In these works, we are interested in natural language understanding. Therefore, we use free-form text but use simple images to ablate vision challenges. As we continue making progress on this front, we want to move closer to our real life goal.
There is an important challenge in pursuing this approach. The solution to the main problem need not be a composition of solution of individual problems.A reinforcement learning algorithm that does well on problems with simple vision challenges like Atari games need not do well on problems with difficult vision challenges like a 3D house.
How do we resolve this? Can we build theoretical models to support our ablations? Turns out we can using the learning reduction approach. For example, we can create an RL algorithm that can solve any Contextual Decision Process by assuming access to solution of elementary problems. Then improving the solution of these elementary problem necessarily improves the overall solution. See this paper and this for examples.
- Debugging and Stress Testing of AI systems: Synthetic datasets can be used for performing a quick sanity check or for stress testing the system. It is often beneficial to design easy but non-trivial synthetic systems such that if you cannot solve them then you have no hope of solving the real problem. This saves money and helps you understand the challenges before going out and building an expensive real life dataset. Alternatively, often times real life problems are not adversarial and do not enable you to stress test your system. For example, if you are building a planning algorithm for navigation then you may not be able to find challenging real life environments (except perhaps this). But why do we want something like that? Cause you do not want to tell a customer that their problem is too hard for your system to solve. If the bot has to navigate in a building that is burning to rescue workers then they must not fail cause the environment is hard to plan for. Synthetic datasets can be used to create an adversarial setup such that if you solve them then you can solve any other problem.
When creating a synthetic dataset you are either aiming for (2) or (3). One must understand this objective prior to collecting the dataset: is it for stress testing, sanity check, ablation? What must be avoided is a rush to create a dataset to flag plant a research idea. Generally, datasets have a longer shell life than solutions and therefore, it is important to get them right.