PAC results with Hoeffding-Bernstein’s inequality are the bread and butter of machine learning theory. In this post, we’ll see how to use Hoeffding’s inequality to derive agnostic PAC bounds with an error rate that decreases as ![O\left(\sqrt{\frac{1}{n}}\right)]() in number of training samples
in number of training samples ![n]() . Then, we’ll see that in the realizable setting we can use Bernstein’s inequality to improve this to
. Then, we’ll see that in the realizable setting we can use Bernstein’s inequality to improve this to ![O\left(\frac{1}{n}\right)]() .
.
Supervised Learning
Consider the task of regression with input space ![\mathcal{X}]() and output space
and output space ![\mathcal{Y}]() . We have access to a model class (also known as hypothesis family)
. We have access to a model class (also known as hypothesis family) ![\mathcal{F} = \left\{ f: \mathcal{X} \rightarrow \mathcal{Y} \right\}]() . We will assume
. We will assume ![\mathcal{F}]() to be finite for simplicity. There exists some unknown data distribution
to be finite for simplicity. There exists some unknown data distribution ![D \in \Delta\left(\mathcal{X} \times \mathcal{Y}\right)]() that is generating examples. Of course, we don’t have access to this data distribution but we have access to some samples from it. Let
that is generating examples. Of course, we don’t have access to this data distribution but we have access to some samples from it. Let ![S = \{(x_i, y_i)\}_{i=1}^n]() be
be ![n]() independent identically distributed (i.i.d) samples from the data distribution i.e.,
independent identically distributed (i.i.d) samples from the data distribution i.e., ![(x_i, y_i) \sim D(.,.)]() and probability of observing a sample
and probability of observing a sample ![S]() is given by
is given by ![P(S) = \prod_{i=1}^n D(x_i, y_i)]() .
.
In order, to evaluate the performance of a model we will need a loss function. Let ![\ell: \mathcal{Y} \times \mathcal{Y} \rightarrow [0, 1]]() be a loss function. Given a datapoint
be a loss function. Given a datapoint ![(x, y)]() and a model
and a model ![f \in \mathcal{F}]() , the loss associated with our prediction is given by
, the loss associated with our prediction is given by ![\ell(y, f(x))]() . For now, we will not make any assumption about
. For now, we will not make any assumption about ![D, \mathcal{F}, \ell]() .
.
Our aim is to find a function ![f \in \mathcal{F}]() that is as good as possible. What is a good function? Well one that has the least loss function across the input space i.e., its generalization error
that is as good as possible. What is a good function? Well one that has the least loss function across the input space i.e., its generalization error ![L_D(f)]() is as low as possible:
is as low as possible: ![L_D(f) = \mathbb{E}_{(x, y) \sim D}\left[\ell(y, f(x)) \right]]() . The only signal we have for finding such a
. The only signal we have for finding such a ![f]() is the training data
is the training data ![S]() . We will define the training error
. We will define the training error ![L_S(f) = \frac{1}{n} \sum_{i=1}^n \ell(y_i, f(x_i))]() . The aim of machine learning theory is to (i) allow us to find a “good”
. The aim of machine learning theory is to (i) allow us to find a “good” ![f]() , and (ii) bound the performance of the predicted model in terms of
, and (ii) bound the performance of the predicted model in terms of ![S, \mathcal{F}]() and other relevant parameters. The first result we will look at is the Occam’s Razor Bound and then we will see how to improve this result.
and other relevant parameters. The first result we will look at is the Occam’s Razor Bound and then we will see how to improve this result.
Occam’s Razor Bound
One of the first result that is taught in a machine learning theory class is the Occam’s Razor bound. The formal result is given in the theorem below. Occam’s Razor bound suggests using the model that minimizes the error on the observed sample ![S]() i.e., the solution of the following optimization:
i.e., the solution of the following optimization: ![\hat{f}_S := \inf_{f \in \mathcal{F}} L_S(f)]() . This solution is called the empirical risk minimizer (ERM) or the ERM solution. We will drop the
. This solution is called the empirical risk minimizer (ERM) or the ERM solution. We will drop the ![S]() from the notation when it is clear from the context.
from the notation when it is clear from the context.
Theorem: Let ![(\mathcal{X}, \mathcal{Y}, D, \ell)]() be a supervised learning problem with input space
be a supervised learning problem with input space ![\mathcal{X}]() , output space
, output space ![\mathcal{Y}]() , data distribution
, data distribution ![D \in \Delta(\mathcal{X} \times \mathcal{Y})]() , and
, and ![\ell: \mathcal{Y} \times \mathcal{Y} \rightarrow [0, 1]]() be the loss function. We are given
be the loss function. We are given ![n]() i.i.d samples
i.i.d samples ![\{(x_i, y_i\}_{i=1}^n]() from the data distribution
from the data distribution ![D]() . Let
. Let ![\mathcal{F}]() be a finite collection of models from
be a finite collection of models from ![\mathcal{X}]() to
to ![\mathcal{Y}]() . Fix any
. Fix any ![\delta \in (0, 1)]() then with probability at least
then with probability at least ![1 - \delta]() over samples
over samples ![S]() drawn i.i.d. from
drawn i.i.d. from ![D]() , we have:
, we have:
![\forall f \in \mathcal{F}, \,\, \left|L_D(f) - L_S(f)\right| < \sqrt{\frac{1}{2n} \log\left(\frac{2|\mathcal{F}|}{\delta}\right)}]() , and
, and
![L_D(\hat{f}) < \inf_{f\in \mathcal{F}} L_D(f) + \sqrt{\frac{2}{n} \log\left(\frac{2|\mathcal{F}|}{\delta}\right)}]() .
.
Proof: Fix any model in the model family ![f \in \mathcal{F}]() . Let
. Let ![Z_i = \ell(y_i, f(x_i))]() . Then observe
. Then observe ![Z_i \in [0, 1]]() and
and ![\{Z_i\}_{i=1}^n]() are i.i.d random variables. They are random variables with respect to the sample
are i.i.d random variables. They are random variables with respect to the sample ![S]() which is randomly chosen. Further,
which is randomly chosen. Further, ![L_S(f) = \frac{1}{n}\sum_{i=1}^n Z_i]() and
and
![\mathbb{E}\left[\frac{1}{n}\sum_{i=1}^n Z_i\right] = \frac{1}{n} \sum_{i=1}^n \mathbb{E}\left[Z_i\right] = \frac{1}{n} \sum_{i=1}^n L_D(f) = L_D(f)]() ,
,
where the first equality follows from linearity of expectation and the second inequality follows from iid assumption. Then using Hoeffding’s inequality:
![P( \left| L_D(f) - L_S(f) \right| \ge t) \le 2\exp^{-2nt^2}]() ,
,
Setting ![\delta = 2\exp^{-2nt^2}]() , we get:
, we get: ![\left|L_D(f) - L_S(f) \right| < \sqrt{\frac{1}{2n}\log\left(\frac{2}{\delta}\right)}]() with probability of at least
with probability of at least ![1 - \delta]() . Let
. Let ![Q_f]() be result derived in the above equation then we have
be result derived in the above equation then we have ![P(Q_f) \ge 1 - \delta]() or in other words
or in other words ![P(\overline{Q_f}) < \delta]() (
(![\overline{X}]() represents the complement of measurable set
represents the complement of measurable set ![X]() ). Even though we derived this result for a fixed
). Even though we derived this result for a fixed ![f]() , we never used any property of
, we never used any property of ![f]() and therefore, it holds for all
and therefore, it holds for all ![f \in \mathcal{F}]() . Therefore, we can bound the probability of
. Therefore, we can bound the probability of ![\cap_{f \in \mathcal{F}} Q_f]() using union bound:
using union bound:
![P(Q_{\hat{f}}) = 1 - P(\overline{Q_{\hat{f}}}) \ge 1 - \sum_{f \in \mathcal{F}} P(\overline{Q_f}) \ge 1 - \sum_{f \in \mathcal{F}} \delta = 1 - \delta |\mathcal{F}|]() .
.
This means with probability of at least ![1 - \delta |\mathcal{F}|]() we have:
we have:
![\forall f \in \mathcal{F}, \,\,\,\,\,\, \left| L_D(f) - L_S(f) \right| < \sqrt{\frac{1}{2n} \log\left(\frac{2}{\delta}\right)}]() .
.
Replacing ![\delta]() by
by ![\frac{\delta}{|\mathcal{F}|}]() proves the first result. Let
proves the first result. Let ![\hat{f}]() be the ERM solution and fix
be the ERM solution and fix ![f]() in
in ![\mathcal{F}]() . Then:
. Then:
![L_D(\hat{f}) < L_S(\hat{f}) + \sqrt{\frac{1}{2n} \log\left(\frac{2|\mathcal{F}|}{\delta}\right)}]() (from Hoeffidng’s inequality)
(from Hoeffidng’s inequality)
![L_S(\hat{f}) \le L_S(f)]() (from the definition of ERM)
(from the definition of ERM)
![L_S(f) < L_D(f) + \sqrt{\frac{1}{2n} \log\left(\frac{2|\mathcal{F}|}{\delta}\right)}]() (from Hoeffidng’s inequality)
(from Hoeffidng’s inequality)
This implies, for any ![f \in \mathcal{F}]() , with probability at least
, with probability at least ![1 - \delta]() :
: ![L_D(\hat{f}) < L_D(f) + \sqrt{\frac{2}{n} \log\left(\frac{2|\mathcal{F}|}{\delta}\right)}]() . As this holds for any
. As this holds for any ![f \in \mathcal{F}]() , therefore, we can pick the
, therefore, we can pick the ![f]() with smallest value of
with smallest value of ![L_D(f)]() . This proves the second result.
. This proves the second result.
There are couple of things that stand out in this result:
- More training data helps: Formally, the bound improves as
![O\left(\sqrt{\frac{1}{n}}\right)]() in sample size
in sample size ![n]() . Informally, this means as we have more training data we will learn a model whose generalized error has a better upper bound.
. Informally, this means as we have more training data we will learn a model whose generalized error has a better upper bound.
- Complex model class can be undesirable: The bound becomes weaker as the model family
![\mathcal{F}]() becomes larger. This is an important lesson in model regularization: if we have two model class
becomes larger. This is an important lesson in model regularization: if we have two model class ![\mathcal{F}_1, \mathcal{F}_2]() that have the same training error on a sample
that have the same training error on a sample ![S]() , then if
, then if ![F_2]() is more complex class than
is more complex class than ![F_1]() i.e.,
i.e., ![|\mathcal{F}_1| < |\mathcal{F}_2|]() , then the bound on the generalization error for the later will be weaker. Note that the result does not say that the larger model class is always bad. We can get better bounds with a more complex model class provided we can appropriately improve the training error.
, then the bound on the generalization error for the later will be weaker. Note that the result does not say that the larger model class is always bad. We can get better bounds with a more complex model class provided we can appropriately improve the training error.
Improving Occam’s Razor Bound with Bernstein’s Inequality
Bernstein’s inequality allows us to incorporate the variance of the random variables in the bound thereby allowing us to get tighter bound for low variance settings.
Theorem (Bernstein’s Inequality): Let ![\left\{X_i\right\}_{i=1}^n]() be
be ![n]() i.i.d random variables with mean
i.i.d random variables with mean ![\mu]() and variance
and variance ![\sigma^2]() . Further, let
. Further, let ![\left|X_i - \mu \right| \le M]() almost surely, for all
almost surely, for all ![i]() . Then:
. Then:
![P\left(\left| \frac{1}{n}\sum_{i=1}^n X_i - \mu \right| > t \right) \le 2\exp\left\{- \frac{3nt^2}{6\sigma^2 + 2Mt} \right\}]()
If the variance was negligible ![\sigma^2 \approx 0]() then we will get
then we will get ![P\left(\left| \frac{1}{n}\sum_{i=1}^n X_i - \mu \right| > t \right) \le 2\exp\left\{-\frac{3nt}{2M}\right\}]() . This bound, if we repeat what we did for Occam’s Razor Bound, will give us
. This bound, if we repeat what we did for Occam’s Razor Bound, will give us ![O\left( \frac{1}{n}\right)]() bound.
bound.
Before we proceed to derive a ![O\left( \frac{1}{n}\right)]() in realizable setting, we will first state the Bernstein’s inequality in the more familiar form. Setting the right hand side to
in realizable setting, we will first state the Bernstein’s inequality in the more familiar form. Setting the right hand side to ![\delta]() and solving the quadratic equation gives us:
and solving the quadratic equation gives us:
With probability at least ![1-\delta]() we have:
we have:
![\left| \frac{1}{n}\sum_{i=1}^n X_i - \mu \right| \le \frac{M}{3n} \log\left( \frac{2}{\delta} \right) + \sqrt{\frac{M^2}{9n^2} \log^2\left(\frac{2}{\delta}\right) + \frac{2\sigma^2}{n}\log\left(\frac{2}{\delta}\right)}]()
We now apply the inequality ![\forall a, b \in [0, \infty), \sqrt{a + b} \le \sqrt{a} + \sqrt{b}]() to get:
to get:
![\left| \frac{1}{n}\sum_{i=1}^n X_i - \mu \right| \le \frac{2M}{3n} \log\left( \frac{2}{\delta} \right) + \sqrt{\frac{2\sigma^2}{n}\log\left(\frac{2}{\delta}\right)}]() .
.
Theorem: Let ![(\mathcal{X}, \mathcal{Y}, D, \ell)]() be a supervised learning problem with input space
be a supervised learning problem with input space ![\mathcal{X}]() , output space
, output space ![\mathcal{Y}]() , data distribution
, data distribution ![D \in \Delta(\mathcal{X} \times \mathcal{Y})]() , and loss function
, and loss function ![\ell \in [0, 1]]() . Let there be
. Let there be ![f^\star \in \mathcal{F}]() such that
such that ![L_D(f^\star) = 0]() . We are given
. We are given ![n]() i.i.d samples
i.i.d samples ![\{(x_i, y_i\}_{i=1}^n]() from the data distribution
from the data distribution ![D]() . Let
. Let ![\mathcal{F}]() be a finite collection of models from
be a finite collection of models from ![\mathcal{X}]() to
to ![\mathcal{Y}]() . Fix any
. Fix any ![\delta \in (0, 1)]() then with probability at least
then with probability at least ![1 - \delta]() we have:
we have:
![L_D(\hat{f}) < \frac{20}{3n} \log\left( \frac{2|\mathcal{F}|}{\delta} \right)]() .
.
Proof: Fix a ![f \in \mathcal{F}]() and define
and define ![\{Z_1, \cdots, Z_n\}]() as before. This time we will apply Bernstein’s inequality. We have
as before. This time we will apply Bernstein’s inequality. We have ![|Z_i - \mu| < 1]() as the loss function is bounded in
as the loss function is bounded in ![[0,1]]() . Bernstein’s inequality gives us:
. Bernstein’s inequality gives us:
![\left|L_D(f) - L_S(f) \right| \le \frac{2}{3n} \log\left( \frac{2}{\delta} \right) + \sqrt{\frac{2\sigma^2}{n}\log\left(\frac{2}{\delta}\right)}]() ,
,
with probability of at least ![1 - \delta]() . All we need to do is bound the variance
. All we need to do is bound the variance ![\sigma^2 = \mathbb{E}_{(x, y) \sim D}[ (\ell(y, f(x)) - L_D(f) )^2] = \mathbb{E}_{(x, y) \sim D}[\ell(y, f(x))^2] - L_D(f)^2]() . As the loss function is bounded in
. As the loss function is bounded in ![[0, 1]]() therefore,
therefore, ![\mathbb{E}_{(x, y) \sim D}[\ell(y, f(x))^2] \le \mathbb{E}_{(x, y) \sim D}[1. \ell(y, f(x))] = L_D(f)]() . This gives us
. This gives us ![\sigma^2 \le L_D(f)]() . Plugging this in we get:
. Plugging this in we get:
![\left|L_D(f) - L_S(f) \right| \le \frac{2}{3n} \log\left( \frac{2}{\delta} \right) + \sqrt{\frac{2L_D(f)}{n}\log\left(\frac{2}{\delta}\right)}]() .
.
Applying AM-GM inequality, we have ![\sqrt{\frac{2L_D(f)}{n}\log\left(\frac{2}{\delta}\right)} < \frac{L_D(f)}{2} + \frac{1}{n}\log\left(\frac{2}{\delta}\right)]() giving us,
giving us,
![\left|L_D(f) - L_S(f) \right| \le \frac{L_D(f)}{2} + \frac{5}{3n} \log\left( \frac{2}{\delta} \right)]() ,
,
with probability ![1-\delta]() . Applying union bound on all hypothesis we get:
. Applying union bound on all hypothesis we get:
![\forall f \in \mathcal{F}, \,\,\,\, \left|L_D(f) - L_S(f) \right| \le \frac{L_D(f)}{2} + \frac{5}{3n} \log\left( \frac{2|\mathcal{F}|}{\delta} \right)]() ,
,
with probability at least ![1-\delta]() . Let
. Let ![\hat{f}]() be the ERM solution then:
be the ERM solution then:
![L_D(\hat{f}) < L_S(\hat{f}) + \frac{L_D(\hat{f})}{2} + \frac{5}{3n} \log\left( \frac{2|\mathcal{F}|}{\delta} \right)]() (Bernstein’s inequality)
(Bernstein’s inequality)
![L_S(\hat{f}) < L_S(f^\star)]() (ERM solution)
(ERM solution)
![L_S(f^\star) < \frac{3}{2}L_D(f^\star) + \frac{5}{3n} \log\left( \frac{2|\mathcal{F}|}{\delta} \right)]() (Bernstein’s inequality)
(Bernstein’s inequality)
![L_D(f^\star) = 0]() (realizability condition)
(realizability condition)
Combining these we get ![L_D(\hat{f}) < \frac{20}{3n} \log\left( \frac{2|\mathcal{F}|}{\delta} \right)]() with probability at least
with probability at least ![1-\delta]() . Hence, proved.
. Hence, proved.
So what is happening? We are making a realizability assumption i.e., there is a function ![f^\star \in \mathcal{F}]() such that
such that ![L_D(f^\star) = 0]() . As the loss is lower bounded by 0, therefore, the variance of the samples of its loss are 0. Now as our ERM solver is becoming better with more data, it is converging towards this
. As the loss is lower bounded by 0, therefore, the variance of the samples of its loss are 0. Now as our ERM solver is becoming better with more data, it is converging towards this ![f^\star]() whose variance is 0. Therefore, the variance of the ERM (which is bounded by its mean
whose variance is 0. Therefore, the variance of the ERM (which is bounded by its mean ![\mu]() ) is becoming smaller. This helps in bounding the rate of convergence.
) is becoming smaller. This helps in bounding the rate of convergence.
Summary: We saw how Hoeffding’s inequality gives us a ![O(\sqrt{\frac{1}{n}})]() bound in number of samples
bound in number of samples ![n]() . When we are in the realizable case, we can get
. When we are in the realizable case, we can get ![O(\frac{1}{n})]() using Bernstein’s inequality.
using Bernstein’s inequality.

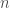








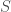

![\ell: \mathcal{Y} \times \mathcal{Y} \rightarrow [0, 1]](http://s0.wp.com/latex.php?latex=%5Cell%3A+%5Cmathcal%7BY%7D+%5Ctimes+%5Cmathcal%7BY%7D+%5Crightarrow+%5B0%2C+1%5D&bg=ffffff&fg=404040&s=0&c=20201002)





![L_D(f) = \mathbb{E}_{(x, y) \sim D}\left[\ell(y, f(x)) \right]](http://s0.wp.com/latex.php?latex=L_D%28f%29+%3D+%5Cmathbb%7BE%7D_%7B%28x%2C+y%29+%5Csim+D%7D%5Cleft%5B%5Cell%28y%2C+f%28x%29%29+%5Cright%5D&bg=ffffff&fg=404040&s=0&c=20201002)
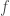






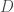

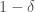



![Z_i \in [0, 1]](http://s0.wp.com/latex.php?latex=Z_i+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=404040&s=0&c=20201002)


![\mathbb{E}\left[\frac{1}{n}\sum_{i=1}^n Z_i\right] = \frac{1}{n} \sum_{i=1}^n \mathbb{E}\left[Z_i\right] = \frac{1}{n} \sum_{i=1}^n L_D(f) = L_D(f)](http://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+Z_i%5Cright%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+%5Cmathbb%7BE%7D%5Cleft%5BZ_i%5Cright%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+L_D%28f%29+%3D+L_D%28f%29&bg=ffffff&fg=404040&s=1&c=20201002)












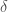






 that have the same training error on a sample
that have the same training error on a sample  is more complex class than
is more complex class than  i.e.,
i.e.,  , then the bound on the generalization error for the later will be weaker. Note that the result does not say that the larger model class is always bad. We can get better bounds with a more complex model class provided we can appropriately improve the training error.
, then the bound on the generalization error for the later will be weaker. Note that the result does not say that the larger model class is always bad. We can get better bounds with a more complex model class provided we can appropriately improve the training error.



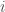








![\ell \in [0, 1]](http://s0.wp.com/latex.php?latex=%5Cell+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=404040&s=0&c=20201002)





![[0,1]](http://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002)

![\sigma^2 = \mathbb{E}_{(x, y) \sim D}[ (\ell(y, f(x)) - L_D(f) )^2] = \mathbb{E}_{(x, y) \sim D}[\ell(y, f(x))^2] - L_D(f)^2](http://s0.wp.com/latex.php?latex=%5Csigma%5E2+%3D+%5Cmathbb%7BE%7D_%7B%28x%2C+y%29+%5Csim+D%7D%5B+%28%5Cell%28y%2C+f%28x%29%29+-+L_D%28f%29+%29%5E2%5D+%3D+%5Cmathbb%7BE%7D_%7B%28x%2C+y%29+%5Csim+D%7D%5B%5Cell%28y%2C+f%28x%29%29%5E2%5D+-+L_D%28f%29%5E2&bg=ffffff&fg=404040&s=0&c=20201002)
![[0, 1]](http://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![\mathbb{E}_{(x, y) \sim D}[\ell(y, f(x))^2] \le \mathbb{E}_{(x, y) \sim D}[1. \ell(y, f(x))] = L_D(f)](http://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%28x%2C+y%29+%5Csim+D%7D%5B%5Cell%28y%2C+f%28x%29%29%5E2%5D+%5Cle+%5Cmathbb%7BE%7D_%7B%28x%2C+y%29+%5Csim+D%7D%5B1.+%5Cell%28y%2C+f%28x%29%29%5D+%3D+L_D%28f%29&bg=ffffff&fg=404040&s=0&c=20201002)











